assembly.AreaRNNWillshaw¶
- class assembly.AreaRNNWillshaw(*in_features: int, out_features, p_synapse=0.05, recurrent_coef=1, **ignored)[source]¶
Bases:
assembly.areas.AreaRNNNon-Holographic Associative Memory Area [1]: a recurrent neural network with one or more incoming input layers and only one output layer. The weights are sparse and binary.
The update rule, if
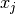 and
and 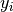 neurons fired:
neurons fired:(1)¶
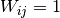
This update rule is the simplest possible update rule that requires neither the learning rate nor the weight normalization, compared to
AreaRNNHebb.- Parameters
- *in_features
The sizes of input vectors from incoming areas.
- out_featuresint
The size of the output layer.
- p_synapsefloat, optional
The initial probability of recurrent and afferent synaptic connectivity. Default: 0.05
- recurrent_coeffloat, optional
The recurrent coefficient
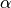 in (1).
Default: 1.0
in (1).
Default: 1.0
References
- 1
Willshaw, D. J., Buneman, O. P., & Longuet-Higgins, H. C. (1969). Non-holographic associative memory. Nature, 222(5197), 960-962.
Methods
complete_from_input(xs_partial[, y_partial])Complete the pattern from the partial input.
complete_pattern(y_partial)Complete the pattern using the recurrent connections only.
forward(xs_stim[, y_latent])The forward pass (1).
Computes the used memory bits as
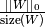
Normalize the pre-synaptic weights sum to
1.0.recall(xs_stim)A forward pass without latent activations.
update_weight(weight, x, y)Update the weight, given the activations.
Attributes
- complete_from_input(xs_partial, y_partial=None)¶
Complete the pattern from the partial input.
Nothing more than a simple forward pass without updating the weights.
- Parameters
- xs_partialtorch.Tensor or tuple of torch.Tensor
Partially active input vectors from the incoming areas.
- y_partialtorch.Tensor or None, optional
The stored latent (hidden activations) vector from the previous step with partial activations. Default: None
- Returns
- y_outtorch.Tensor
The output vector.
- complete_pattern(y_partial)¶
Complete the pattern using the recurrent connections only.
- Parameters
- y_partialtorch.Tensor
A partially activated latent vector.
- Returns
- ytorch.Tensor
The reconstructed vector y.
- forward(xs_stim, y_latent=None)¶
The forward pass (1).
- Parameters
- xs_stimtorch.Tensor or tuple of torch.Tensor
Input vectors from the incoming areas.
- y_latenttorch.Tensor or None, optional
The stored latent (hidden activations) vector from the previous step. Default: None
- Returns
- y_outtorch.Tensor
The output vector.
- memory_used()¶
Computes the used memory bits as
- Returns
- dict
A dictionary with used memory for each parameter (weight matrix).
- normalize_weights()¶
Normalize the pre-synaptic weights sum to
1.0.Without the normalization, all inputs converge to the same output vector determined by the lateral weights because the sum
w_xy @ x + w_lat @ yfavors the second element. Normalization of the feedforward and lateral weights makesw_xy @ xandw_lat @ yof the same magnitude.
- recall(xs_stim)¶
A forward pass without latent activations.
- Parameters
- xs_stimtorch.Tensor or tuple of torch.Tensor
Input vectors from the incoming areas.
- Returns
- y_outtorch.Tensor
The output vector.