assembly.AreaSequential¶
- class assembly.AreaSequential(*args: torch.nn.modules.module.Module)[source]¶
- class assembly.AreaSequential(arg: OrderedDict[str, Module])
Bases:
torch.nn.modules.container.Sequential,assembly.areas.AreaInterfaceA sequence of areas. The output of one area is fed into the next area.
Methods
complete_from_input(xs_partial[, y_partial])Complete the pattern from the partial input.
forward(xs_stim[, y_latent])Defines the computation performed at every call.
Computes the used memory bits as
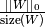
Normalize the pre-synaptic weights sum to
1.0.recall(xs_stim)A forward pass without latent activations.
Attributes
- complete_from_input(xs_partial, y_partial=None)¶
Complete the pattern from the partial input.
Nothing more than a simple forward pass without updating the weights.
- Parameters
- xs_partialtorch.Tensor or tuple of torch.Tensor
Partially active input vectors from the incoming areas.
- y_partialtorch.Tensor or None, optional
The stored latent (hidden activations) vector from the previous step with partial activations. Default: None
- Returns
- y_outtorch.Tensor
The output vector.
- forward(xs_stim, y_latent=None)[source]¶
Defines the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- memory_used()¶
Computes the used memory bits as
- Returns
- dict
A dictionary with used memory for each parameter (weight matrix).
- normalize_weights()¶
Normalize the pre-synaptic weights sum to
1.0.Without the normalization, all inputs converge to the same output vector determined by the lateral weights because the sum
w_xy @ x + w_lat @ yfavors the second element. Normalization of the feedforward and lateral weights makesw_xy @ xandw_lat @ yof the same magnitude.